
Bài viết này sẽ cung cấp cho bạn cái nhìn sơ lược về năm công cụ nguồn mở phổ biến có thể được sử dụng để tạo nền tảng phân tích dữ liệu.
Dữ liệu lớn là dữ liệu theo thứ tự terabyte hoặc petabyte và hơn thế nữa, bao gồm khai thác, phân tích và mô hình dự đoán của các tập dữ liệu lớn. Sự phát triển nhanh chóng của thông tin và phát triển công nghệ đã tạo cơ hội duy nhất cho các cá nhân và doanh nghiệp trên toàn thế giới thu được lợi nhuận và phát triển các khả năng mới để xác định lại các mô hình kinh doanh truyền thống bằng cách sử dụng phân tích quy mô lớn.
Bài viết này cung cấp cái nhìn toàn cảnh về năm nền tảng dữ liệu nguồn mở phổ biến nhất. Đây là danh sách của chúng tôi:
Apache Hadoop
Apache Hadoop là một nền tảng phần mềm mã nguồn mở xử lý các tập dữ liệu rất lớn trong môi trường phân tán liên quan đến khả năng lưu trữ và tính toán, và chủ yếu được xây dựng trên phần cứng hàng hóa giá rẻ.
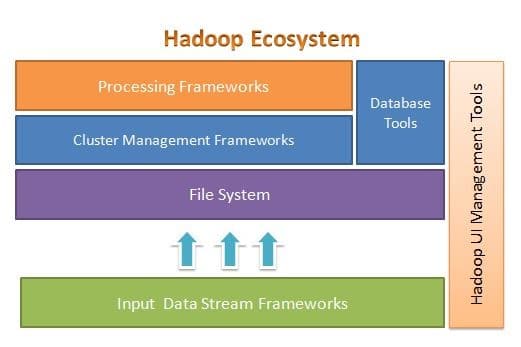
Apache Hadoop được thiết kế để dễ dàng mở rộng quy mô từ vài đến hàng nghìn máy chủ. Nó giúp bạn xử lý dữ liệu được lưu trữ cục bộ trong một thiết lập xử lý song song tổng thể. Một trong những lợi ích của Hadoop là nó xử lý lỗi ở cấp độ phần mềm. Hình sau minh họa kiến trúc tổng thể của Hệ sinh thái Hadoop và vị trí của các khuôn khổ khác nhau bên trong nó:
Apache Hadoop cung cấp một khuôn khổ cho lớp hệ thống tệp, lớp quản lý cụm và lớp xử lý. Nó để lại một tùy chọn cho các dự án và khuôn khổ khác đến và hoạt động cùng với Hệ sinh thái Hadoop và phát triển khuôn khổ của riêng chúng cho bất kỳ lớp nào có sẵn trong hệ thống.
Apache Hadoop bao gồm bốn mô-đun chính. Các mô-đun này là Hệ thống tệp phân tán Hadoop (lớp hệ thống tệp), Hadoop MapReduce (hoạt động với cả quản lý cụm và lớp xử lý), Yet Another Resource Negotiator (YARN, lớp quản lý cụm) và Hadoop Common.
Elasticsearch
Elasticsearch là một công cụ phân tích và tìm kiếm dựa trên văn bản đầy đủ. Nó là một hệ thống phân tán và có khả năng mở rộng cao, được thiết kế đặc biệt để làm việc hiệu quả và nhanh chóng với các hệ thống dữ liệu lớn, trong đó một trong những trường hợp sử dụng chính của nó là phân tích nhật ký. Nó có khả năng thực hiện các tìm kiếm nâng cao và phức tạp, đồng thời xử lý gần như theo thời gian thực để phân tích nâng cao và thông minh hoạt động.

Elasticsearch được viết bằng Java và dựa trên Apache Lucene. Được phát hành vào năm 2010 và nó nhanh chóng trở nên phổ biến vì cấu trúc dữ liệu linh hoạt, kiến trúc có thể mở rộng và thời gian phản hồi rất nhanh. Elasticsearch dựa trên tài liệu JSON với cấu trúc không có giản đồ, giúp việc sử dụng dễ dàng và không gặp rắc rối. Nó là một trong những công cụ tìm kiếm xếp hạng hàng đầu của cấp doanh nghiệp. Bạn có thể viết ứng dụng khách của nó bằng bất kỳ ngôn ngữ lập trình nào; Elasticsearch chính thức hoạt động với Java, .NET, PHP, Python, Perl, v.v.
Elasticsearch chủ yếu tương tác bằng API REST. Nó lấy dữ liệu ở dạng tài liệu JSON với tất cả các tham số bắt buộc và cung cấp phản hồi của nó theo cách tương tự.
MongoDB
MongoDB là một cơ sở dữ liệu NoSQL dựa trên mô hình dữ liệu lưu trữ tài liệu. Trong MongoDB, mọi thứ đều là bộ sưu tập hoặc tài liệu. Để hiểu thuật ngữ MongoDB, collection là một từ thay thế cho bảng, trong khi document là một từ thay thế cho các hàng.

MongoDB là một cơ sở dữ liệu mã nguồn mở, hướng tài liệu và đa nền tảng. Nó chủ yếu được viết bằng C ++. Nó cũng là cơ sở dữ liệu NoSQL hàng đầu cung cấp hiệu suất cao, tính sẵn sàng cao và khả năng mở rộng dễ dàng. MongoDB sử dụng các tài liệu giống JSON với lược đồ và cung cấp hỗ trợ truy vấn phong phú. Một số tính năng chính của nó bao gồm lập chỉ mục, sao chép, cân bằng tải, tổng hợp và lưu trữ tệp.
Cassandra
Cassandra là một Dự án Apache mã nguồn mở được thiết kế để quản lý cơ sở dữ liệu NoSQL. Các hàng Cassandra được sắp xếp thành các bảng và được lập chỉ mục bằng một khóa. Nó sử dụng một công cụ lưu trữ dựa trên nhật ký, chỉ phần phụ. Dữ liệu trong Cassandra được phân phối trên nhiều nút không có chủ, không có điểm lỗi nào. Đây là một dự án Apache cấp cao nhất và sự phát triển của nó hiện đang được Tổ chức Phần mềm Apache (ASF) giám sát.
Cassandra được thiết kế để giải quyết các vấn đề liên quan đến hoạt động ở quy mô lớn (web). Với kiến trúc không có chủ của Cassandra, nó có thể tiếp tục thực hiện các hoạt động mặc dù có một số lỗi phần cứng nhỏ (mặc dù đáng kể). Cassandra chạy trên nhiều nút trên nhiều trung tâm dữ liệu. Nó sao chép dữ liệu qua các trung tâm dữ liệu này để tránh thất bại hoặc thời gian chết. Điều này làm cho nó trở thành một hệ thống có khả năng chịu lỗi cao.
Cassandra sử dụng ngôn ngữ lập trình của riêng mình để truy cập dữ liệu trên các nút của nó. Nó được gọi là Ngôn ngữ truy vấn Cassandra hoặc CQL. Nó tương tự như SQL, được sử dụng chủ yếu bởi Cơ sở dữ liệu quan hệ. CQL có thể được sử dụng bằng cách chạy ứng dụng riêng của nó có tên là cqlsh. Cassandra cũng cung cấp nhiều giao diện tích hợp cho nhiều ngôn ngữ lập trình để xây dựng một ứng dụng sử dụng Cassandra. API tích hợp của nó hỗ trợ Java, C ++, Python và những thứ khác.
Apache HBase
HBase là một Dự án Apache khác được thiết kế để quản lý kho dữ liệu NoSQL. Nó được thiết kế để sử dụng các tính năng của Hệ sinh thái Hadoop, bao gồm độ tin cậy, khả năng chịu lỗi, v.v. Nó sử dụng HDFS làm hệ thống tệp cho mục đích lưu trữ. Có nhiều mô hình dữ liệu mà NoSQL làm việc với và Apache HBase thuộc về mô hình dữ liệu hướng cột. HBase ban đầu dựa trên Google Big Table, cũng liên quan đến mô hình hướng cột cho dữ liệu phi cấu trúc.
HBase lưu trữ mọi thứ dưới dạng một cặp khóa-giá trị. Điều quan trọng cần lưu ý là trong HBase, một khóa và một giá trị ở dạng byte. Vì vậy, để lưu trữ bất kỳ thông tin nào trong HBase, bạn phải chuyển đổi thông tin thành byte. (Nói cách khác, API của nó không chấp nhận bất kỳ thứ gì khác ngoài mảng byte.) Hãy cẩn thận với HBase, vì khi bạn lưu trữ dữ liệu, bạn nên nhớ kiểu gốc của nó. Dữ liệu ban đầu là một chuỗi sẽ trả về dưới dạng một mảng byte nếu được gọi sai. Kết quả là nó sẽ tạo ra một lỗi trong ứng dụng của bạn và làm ứng dụng của bạn bị treo.
Viettelco hy vọng bài viết này đã đem lại cho bạn kiến thức về một số nền tảng bigdata mã nguồn mở. Từ đó bạn có thể xây dựng hệ thống dữ liệu chuyên sâu thông minh bằng cách kết hợp các lõi dữ liệu chuyên sâu kiến trúc nguyên tắc, mô hình và kỹ thuật trực tiếp vào kiến trúc ứng dụng của bạn.